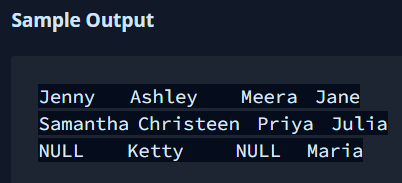
1. Weather Observation Station 6
Query the list of CITY names starting with vowels (i.e., a, e, i, o, or u) from STATION. Your result cannot contain duplicates.

2. Weather Observation Station 7
Query the list of CITY names ending with vowels (a, e, i, o, u) from STATION. Your result cannot contain duplicates.

3. Weather Observation Station 8
Query the list of CITY names from STATION which have vowels (i.e., a, e, i, o, and u) as both their first and last characters. Your result cannot contain duplicates.

4. Weather Observation Station 18
Consider P1(a,c) and P2(b,d) to be two points on a 2D plane.
a happens to equal the minimum value in Northern Latitude (LAT_N in STATION).
b happens to equal the minimum value in Western Longitude (LONG_W in STATION).
c happens to equal the maximum value in Northern Latitude (LAT_N in STATION).
d happens to equal the maximum value in Western Longitude (LONG_W in STATION).
Query the Manhattan Distance between points P1 and P2 and round it to a scale of 4 decimal places.

5. Weather Observation Station 19
Consider P1(a,c) and P2(b, d) to be two points on a 2D plane where (a,b) are the respective minimum and maximum values of Northern Latitude (LAT_N) and (c,d) are the respective minimum and maximum values of Western Longitude (LONG_W) in STATION.
Query the Euclidean Distance between points P1 and P2 and format your answer to display 4 decimal digits.

'Data > SQL' 카테고리의 다른 글
| [프로그래머스] 특정 기간동안 대여 가능한 자동차들의 대여비용 구하기 (0) | 2023.03.04 |
|---|---|
| [HackerRank] The Report (0) | 2023.02.15 |
| [HackerRank] Occupations, The PADS. 문제 풀이 (MySQL) (0) | 2023.02.06 |
| [SQLZOO] JOIN 문제 풀이 (0) | 2023.02.01 |
| [프로그래머스] SQL Kit 문제 풀이(2) (0) | 2023.01.29 |